AI 把写代码从 3 天压到半天,整个项目却只快了 10%
一封邮件
月初,我们公司发了一封内部邮件。
邮件不是很长,主要就是说:接下来 AI 工具的使用会有三个月的”观察期”,三个月后视情况再调整。
虽然没有直说,但是大家都懂,以后大概率不能无限使用最好的模型了。
让我印象深的是翻转的速度。
就在不久之前,风向还完全是反的:内部鼓励大家放开了用,token 不设上限,最新最强的模型随便调。
那阵子甚至有不少新闻说,一些大厂直接把员工的 token 用量和绩效、晋升挂钩,用得越多越”拥抱变化”,连 manager 的考评都跟团队的 AI 使用量绑定。
口号还是”用得越多越好”。结果没过几个月,就从”鼓励”换成了”观察”。
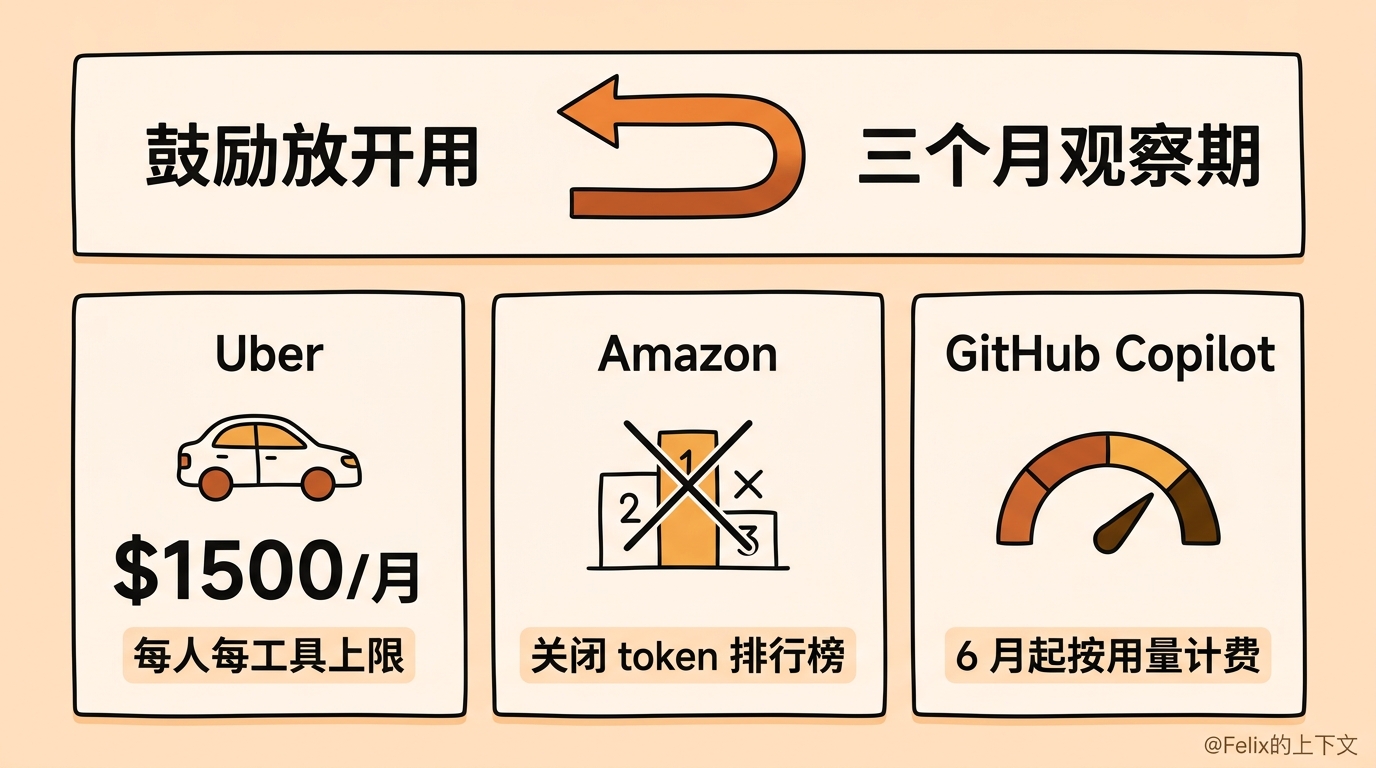
这也不是我们一家的事。最近这类新闻特别密集:
- Uber 给员工用 Claude Code、Cursor 这类工具设了每人每工具每月 1500 美元的 token 上限,因为它的 AI coding 预算据说四个月就烧完了一整年的额度;
- Amazon 关掉了内部那个 AI token 用量排行榜,因为员工为了冲榜疯狂刷 token,制造了一堆没意义的消耗;
- GitHub Copilot 从 6 月起改成按用量计费,理由是 agentic coding 一个 session 的成本和普通聊天差太多,原来的定价”不再可持续”。
放在一起看,有一个很明显的变化:企业正在从”鼓励大家用 AI”,转向”追问 AI 到底换来了什么”。
第一反应往往是错的
很多人看到这些新闻,第一反应是:是不是 AI 其实没那么有用?泡沫要破了?
我不这么看。
更准确的说法是:AI 的成本是当下就发生的,账单一笔笔清清楚楚;可它换来的好处呢,往往说不清、看不见,还很难算到谁头上。
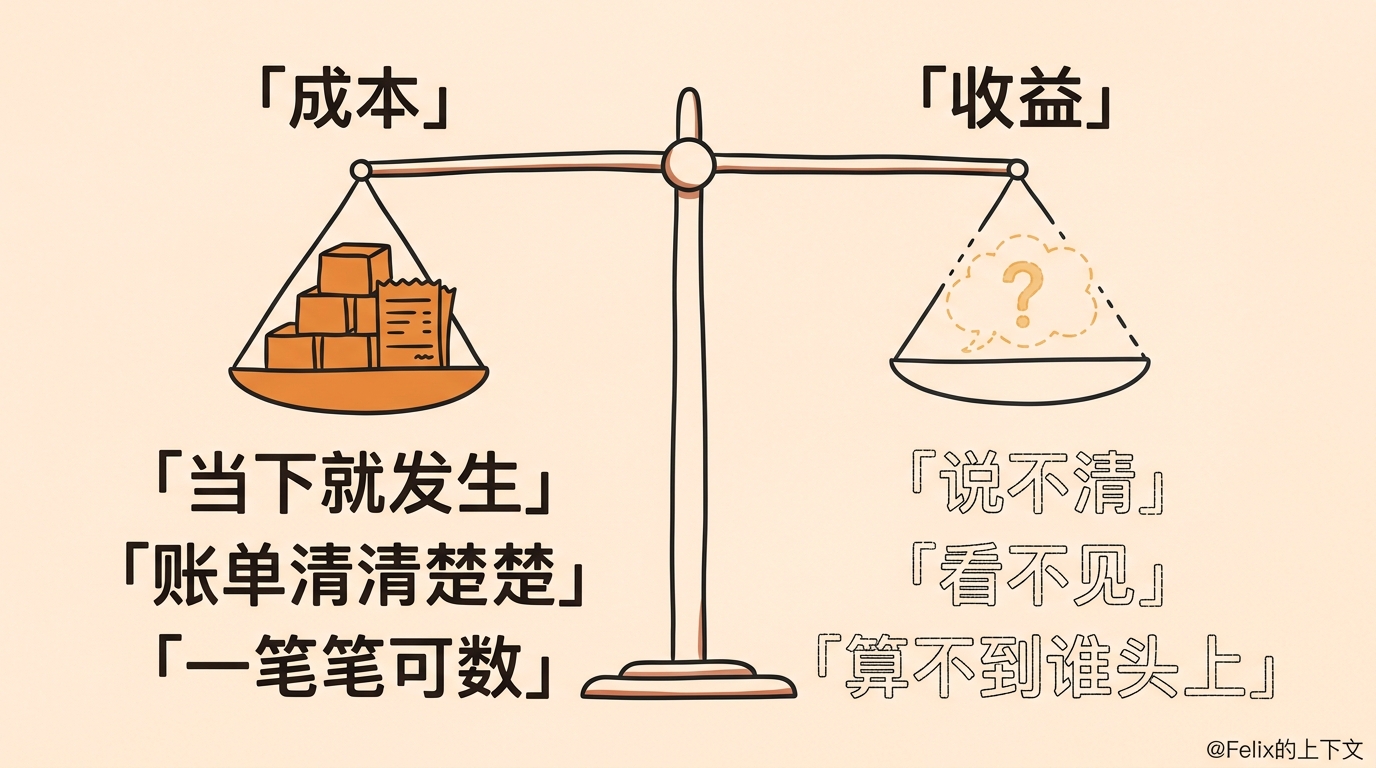
之前那波”无限用”,说白了是企业在做 adoption。 先不算账,让所有人先把 AI 用起来再说。可当 token、seat、企业 API 的账单真真切切发生的时候,问题就绕不开了:这些钱,到底换来了什么?
Uber 那个例子特别典型。它的 COO 说得很直白:很难把 Claude Code 这类工具的使用量,和”我们到底多交付了多少真正有用的功能”对上号。
这话扎心的地方,在”证明不了”这几个字:东西可能真做出来了,但谁也没法把它和实打实的业务结果对上号。
这其实是企业心态的一个转变:以前比的是谁用得多,现在要问的是这些 token 换来了什么。
但如果只停在这一层,我觉得还没说到根上。”ROI 不行”只是结果,我更想聊的是它背后的原因。
我们其实只让 AI 干了最小的一段活
我自己就在公司里做 AI 相关的工作,所以对这件事有些挺具体的体感。
现在大家用 AI 用得最多的,说到底还是写代码。再宽一点,是写代码、debug、补测试这些跟编码强相关的事。
但问题就在这儿:对一个产品、一个大型组织来说,写代码在整个生命周期里只占很小的一块。
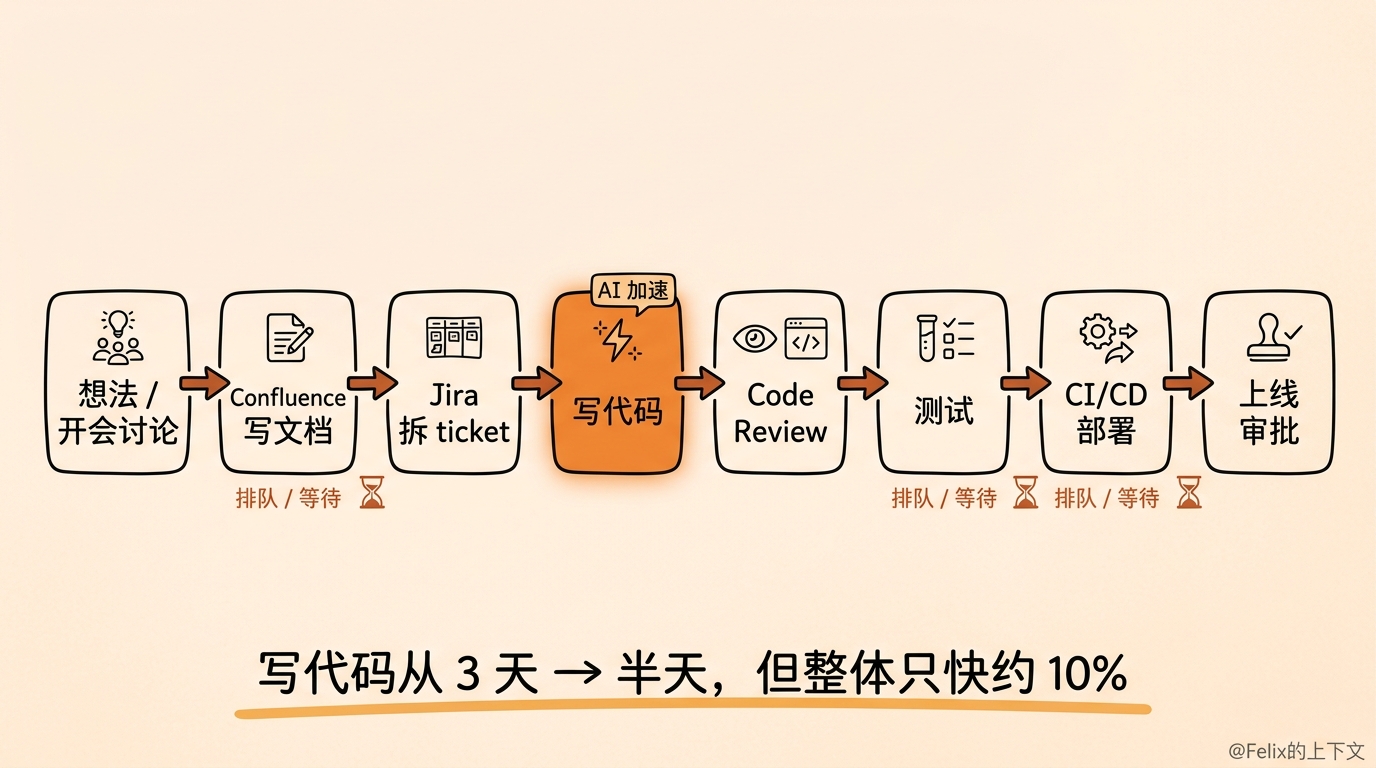
举个再普通不过的例子。我们要做一个新功能,流程大概是这样的:
先有个 idea,几个人开会讨论,在 Confluence 上建几个页面记下来;然后在 Jira 上拆出 epic、story、task,ticket 底下还有一堆 comment 来回确认;接着才轮到开发——工程师领了 ticket 去写代码;写完要 review、要测试(单元测试、回归测试,有时候还得手工测);再往后是 CI/CD、部署、上线审批、回滚预案……这中间还经常卡在 infra 上,而 infra 在很多大公司出于安全考虑,AI 是根本碰不到的。
你数一数,AI 现在真正在加速的是哪一步?
就中间”写代码”那一小段。
所以哪怕 AI 把写代码从三天压到半天,可只要需求还得讨论一周、review 还得等两天、测试环境还得排队、上线还得走审批,整个项目周期可能就快了 10%,甚至几乎没动。
这就是我想说的第一个核心:AI 提升的是局部效率,企业要的却是端到端的吞吐量。
比如我们现在一个 PR 平均需要 review 10 天才能合并到主分支,虽然写代码变快了,但是总体效率几乎没有提升。
程序员个人的体感是真的爽,代码刷刷地出。但组织层面的交付速度,没怎么动。于是企业一看账单就尴尬了——钱没少花,那个”快”却没传导到它真正在乎的地方:交付周期、质量、成本、收入。
再深一层:旧流程把 AI 的能力截断了
如果再往下挖,会碰到一个更结构性的问题。
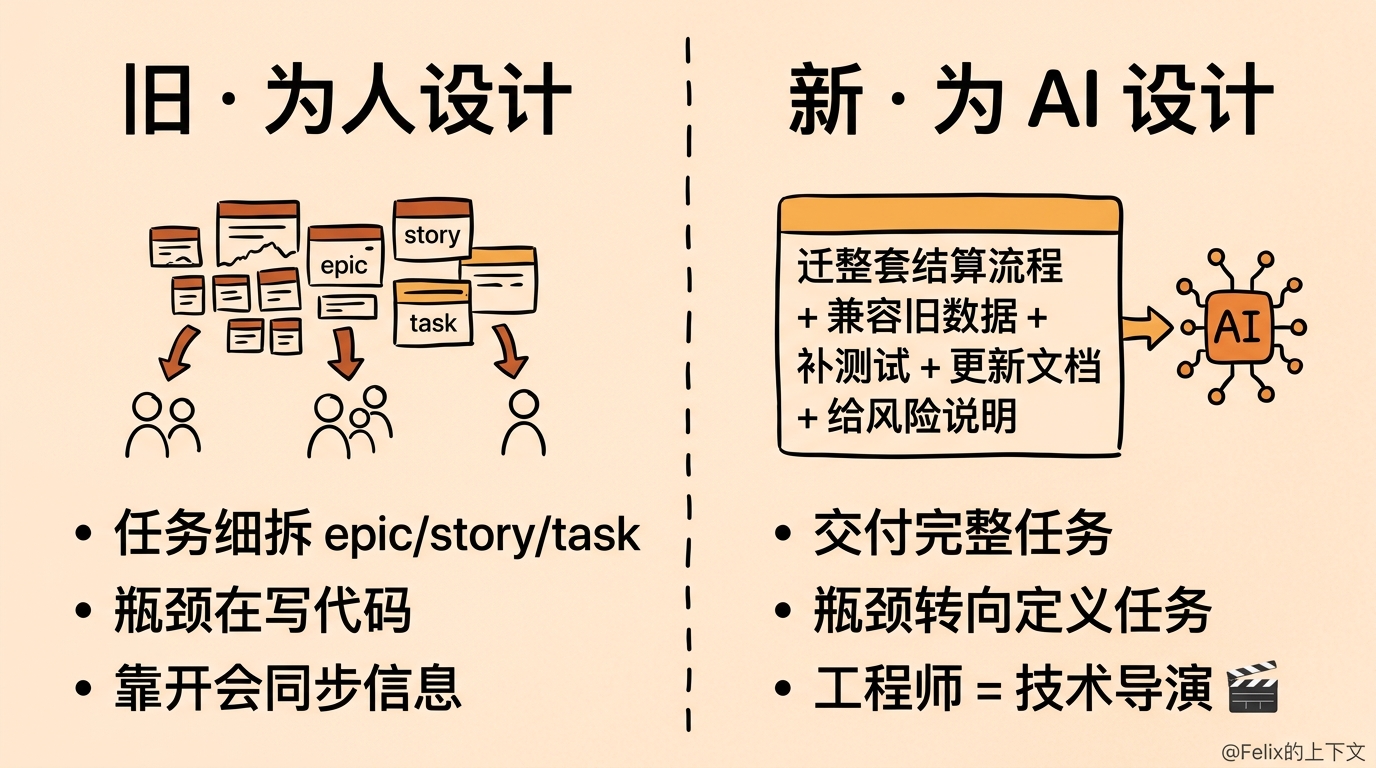
我们今天这套软件开发流程,骨子里是为人设计的。
Confluence 写文档,Jira 拆任务,GitHub 写代码,CI/CD 跑流水线,Teams 和 Slack 沟通,开会做同步——这套东西背后的假设是:人的记忆有限、上下文切换慢、协作得显式记录、责任要层层拆分。所以才把一件事切成一个个小环节,按人的能力和职责分下去。
然后我们做了什么?我们把 AI 塞进了这些为人切好的小格子里。
这里其实有两处损耗。
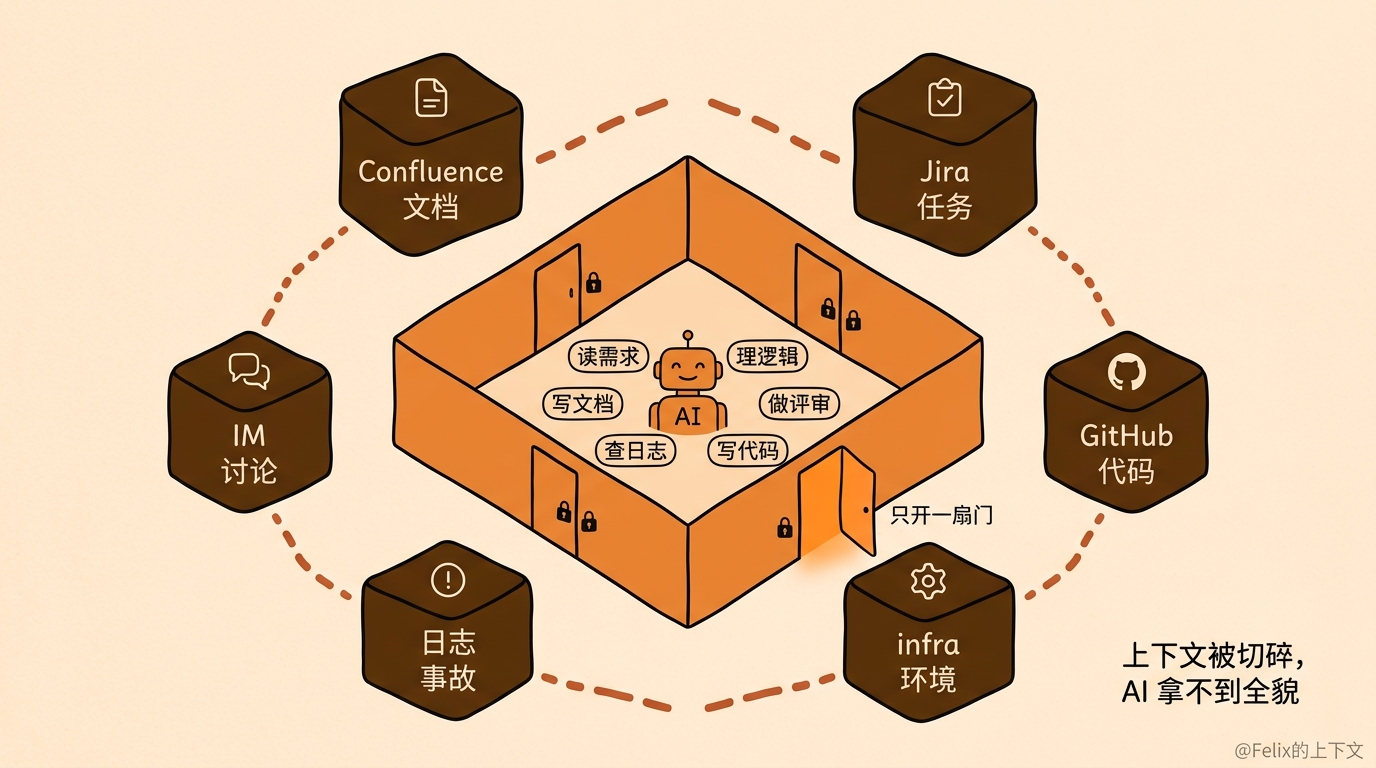
一是 AI 几乎在每个环节能力都不弱,旧流程却只给了它一个格子。 AI 不是只会写代码,它读需求、理逻辑、写文档、做评审、查日志,样样不差。可现在的用法是:只在”写代码”那一格放它进来,别的门对它都关着。等于拿一套为人类分工设计的流程,反过来把 AI 框死了。
二是 信息被切碎在不同系统里,AI 根本拿不到完整上下文。 文档在 Confluence,任务在 Jira,代码在 GitHub,环境信息在 infra,事故在日志,讨论散在各种 IM 里。这些本来彼此关联的信息,被切成了一块一块。对一个 coding agent 来说,它要是只能看到代码库,就不知道业务背景、不知道当初为什么这么设计、不知道线上有什么约束、不知道用户怎么反馈。
我猜在很多公司里,AI 想拿到这些上下文都挺难的,你得自己去外挂 MCP、配 skills、一个个把系统打通,而很多传统企业压根没做这层基础设施。结果就是 AI 只摸得到代码,别的都够不着。
一个拿不到上下文的 AI,只能靠猜。它再强,也只能退化成一个更快的代码补全器。
打个比方,这就像你买了辆车,却非要它走马车时代的路、按马车的规矩调度,最后回头嘀咕一句”这车好像也没快多少”,其实车没毛病,是路还没修。
那接下来会怎么变
只买 AI 编程工具,远远不够。真正值钱的,是把 AI 接进完整的工作流——需求、代码、测试、发布、运维、知识库,都在一个连续的上下文里流动,而不是散在几个互不打通的系统里。换句话说,未来企业里最值钱的,也许是它内部那层”上下文基础设施”:代码、文档、决策、线上数据,到底能不能被 AI 安全、完整地读到。很多公司现在 AI 效果差,真不怪模型,怪的是上下文散得太碎。
任务本身的颗粒度会变。人类协作必须把任务切得很细,因为一个人一次只扛得动一小块;可 AI 一次能吞下的上下文大得多。所以以后交给 AI 的,可能不再是”改一下这个字段”这种零碎操作,而是”把这套结算流程迁到新规则,兼容旧数据、补齐测试、更新文档,再给我一份风险说明”这种完整的任务。Jira 那种 epic、story、task 的细拆法,本来就是为人准备的。
这件事反过来又会改变工程师的价值。实现越来越快,瓶颈就从”写代码”挪到了”定义任务”:你能不能把问题说清楚,能不能给 AI 喂对上下文,能不能判断方案好不好,能不能把一堆拧巴的业务约束翻译成可执行的目标。我越来越觉得,以后好的工程师会更像一个技术导演:定目标、给约束、审结果、扛风险,写代码反倒成了其中最不费劲的一环。
再往上,连一部分管理动作都会被重新掂量。我们今天开的很多会、对的很多状态、同步的很多进度,说到底都是在补”信息不透明”这个窟窿。要是 AI 能持续把进展、风险、阻塞读出来、写出来,那一部分纯粹”对信息”的沟通,是会被压缩的。
最后
绕一圈,回到那封邮件。
我不觉得这轮收紧意味着”AI 不行了”。恰恰相反,它说明企业终于认真起来、开始算账了,这不一定是坏事。
我真正想说的是:今天企业 AI 效果不明显,根子不在模型,而在于我们还没把软件的生产方式,改成适合 AI 的样子。我们把一个全新的生产力,硬塞进了一套为人、为旧时代分工设计的老系统里,它的能力自然被框住了。
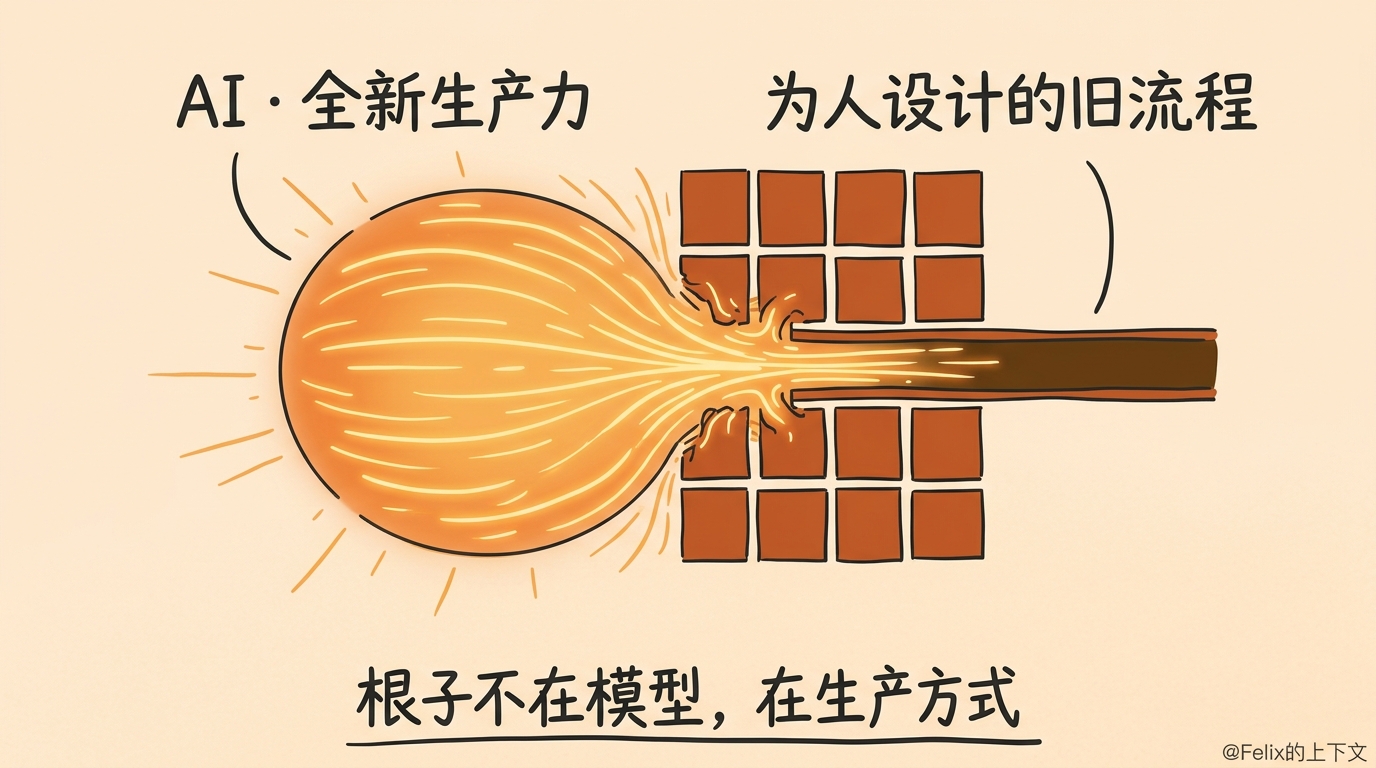
所以预算收紧只是表象。底下那个真问题是:组织还停在旧流程里。
但这也是真正的机会所在。谁能先把 AI 从一个”写代码的工具”,变成一个”能把整件事从头跑到尾”的系统,谁那笔 AI 预算,才算真正花在了刀刃上。